[LLM 활용] LangSmith feedback을 이용한 프롬프트 개선
이번 포스트에서는 LangSmith 서비스의 주요 기능 중 하나인 annotation queue – feedback 을 활용해서 프롬프트를 개선하는 예제를 다룹니다.
예제는 먼저 뉴스 사이트의 텍스트를 가져와서 저장합니다. 그리고 제목/작성자/날짜/요약문 – 4가지 데이터를 추출할 수 있도록 프롬프트를 작성해서 개선해나가는게 목표입니다.
이번 예제의 기본적인 아이디어는 아래 링크를 참고했으며, 동작 오류를 수정하고 코드를 정리해서 좀 더 이해하기 쉽도록 다듬었습니다.
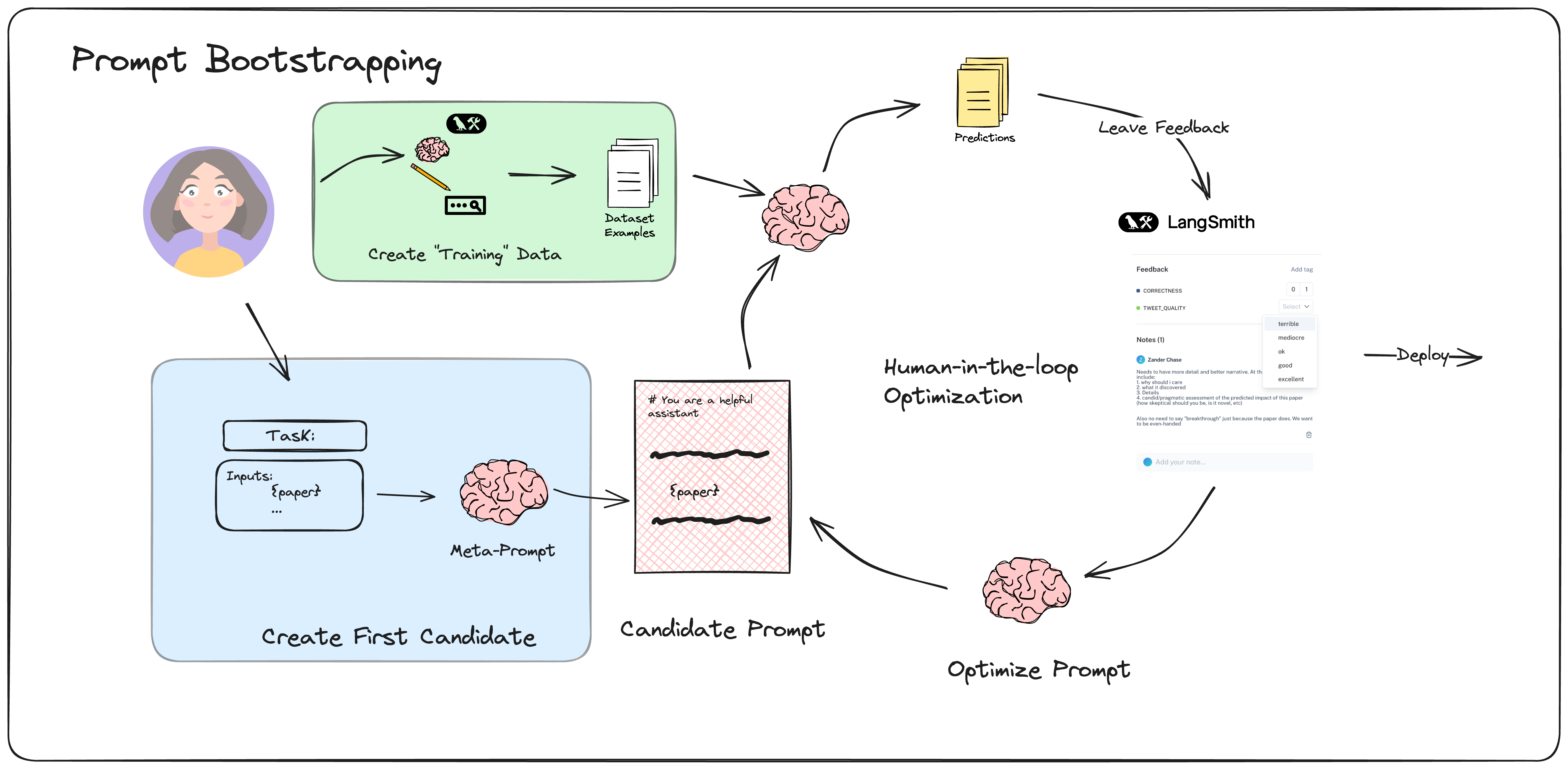
위 프롬프트 개선 프로세스와는 달리 이번 예제에서는 변형된 프로세스를 따릅니다.
- Training 준비 단계 (사진의 초록색 영역)
- 뉴스를 [제목/작성자/날짜/요약문]으로 요약하는 초기 프롬프트를 준비합니다.
- 대상이 되는 뉴스 데이터(뉴스 url 과 스크래핑한 결과)를 준비합니다.
- 스크래핑 한 뉴스 데이터는 추후 LangSmith – Datasets & Testing 메뉴에 저장됩니다.
- 두 개의 초기 프롬프트를 준비합니다.
- 뉴스 요약에 사용할 프롬프트 -> 개선 대상이므로 계속 변경됨
- 프롬프트 개선에 사용할 프롬프트 (고정)
- 두 개의 LLM 모델을 준비합니다.
- 뉴스 요약에 사용할 LLM -> ollama llama3.1 (8b)
- 프롬프트 개선에 사용할 LLM -> OpenAI GPT-4o-mini
- llama3.1 (8b) 는 프롬프트 개선에 사용하기엔 너무 성능이 낮음
- 실험(experiment) 단계 (오른쪽 순환 루프 상단)
- 스크래핑한 뉴스 중 하나를 선택합니다
- LangSmith – Datasets 에 새로운 dataset 을 만들거나 기존 dataset 을 가져옴
- 선택된 dataset 에 example(스크래핑한 뉴스)을 추가합니다.
- example에 뉴스 요약 프롬프트를 적용(run)해서 결과(prediction)를 기록합니다.
- run 과정을 거치면 example 은 experiment 로 바뀌어 표시됩니다.
- example-run 결과를 Annotation queue 에 등록합니다.
- queue 에 RunnableSequence 가 등록되고, 평가자가 (뉴스 요약 결과에) feedback 을 남길 수 있는 상태가 됩니다.
- 평가(feedback) 단계
- 평가자는 Annotation queue 에 등록된 뉴스 요약 결과를 보고 성능을 평가(feedback)합니다.
- correctness : 0 or 1 (요약 항목별 치명적 오류 여부, pass/fail)
- score : 1~5 (평가 점수)
- note (comment): correctness, score 점수를 판단한 구체적인 근거
- 위 항목들은 테스트를 위한 것으므로 실제 프롬프트 엔지니어링의 평가 항목과는 차이가 있습니다.
- 현재 뉴스 요약 결과가 만족스러울 경우 프롬프트를 확정하고 배포(deploy)할 수 있습니다.
- 이 경우 프롬프트 개선 프로세스는 종료됩니다.
- 평가자가 feedback 을 완료하면 해당 항목은 annotation queue 에서 사라집니다.
- feedback 내용은 datasets 에 있는 experiment 항목에 표시됩니다.
- 평가자는 Annotation queue 에 등록된 뉴스 요약 결과를 보고 성능을 평가(feedback)합니다.
- 프롬프트 최적화(optimization) 단계 (오른쪽 루프 하단)
- LangSmith – Datasets 에 등록된 experiment 에서 feedback 정보를 가져옵니다.
- 기사 원문/프롬프트/요약결과/피드백 정보를 결합해서 프롬프트 개선용 프롬프트를 완성합니다.
- 프롬프트 개선용 프롬프트를 사용해서 LLM 모델에게 개선을 요청합니다.
- 이 과정은 LangSmith – Project 메뉴에 기록됩니다.
- 개선된 프롬프트를 확인 -> 2~4 단계를 반복합니다.
다소 복잡한 프로세스이지만, 이 과정을 하나씩 짚어보면 LangSmith 서비스 사용법과 활용방법을 익힐 수 있습니다.
실습에 사용된 소스파일 전체는 링크에서 다운로드 받을 수 있습니다. [LangSmith_prompt_feedback.py]
소스코드가 한 화면에 보기에는 길어서, 여기서는 단계별로 코드를 잘라서 분석합니다.
실습 예제: 1. Training 준비단계
이 단계에서는 앞으로 실행할 프로세스에 필요한 환경설정을 하고 파라미터와 데이터를 준비합니다.
# 1. 프로세스 실행을 위한 환경설정 및 파라미터 준비
# LangSmith 사이트에서 아래 내용을 복사해서 .env 파일에 입력
# LANGCHAIN_TRACING_V2=true
# LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
# LANGCHAIN_API_KEY=<your_api_key>
# LANGCHAIN_PROJECT="<your_project_name>"
load_dotenv() # .env 파일 로드
# 1-1. LangSmith project, dataset, annotation queue 이름으로 사용할 문자열
project_name = os.getenv("LANGCHAIN_PROJECT")
1. 프로세스 실행을 위한 환경설정 및 파라미터 준비
- .env 파일에 환경변수를 입력해야합니다.
- 뒤에서 다시 언급되겠지만 OpenAI API 사용을 위해 OPENAI_API_KEY 도 입력합니다.
- LANGCHAIN_PROJECT 환경변수에는 프로젝트 이름을 입력합니다.
- LangSmith 의 project, datasets, annotation queue 메뉴 아래에 같은 이름으로 폴더가 생성됩니다
- 예제에서는 “News summarizer” 로 사용합니다.
테스트 할 3개의 뉴스 URL, 임시저장용 파라미터, LangSmith client 를 준비합니다.
# 1-2. 테스트 대상이 되는 뉴스 URLs
news_urls = [
"""https://www.bbc.com/korean/articles/c166p510n79o""",
"""https://www.bbc.com/korean/articles/cjqe104j8l0o""",
"""https://www.bbc.com/korean/articles/c2lewq29ww7o""",
]
data_cache = {} # 데이터 임시 저장용 캐시 생성
# 1-3. langsmith client 생성
client = Client()
2개의 프롬프트를 준비합니다.
# 1-4. 뉴스 요약 PROMPT Template 생성
prompt = PromptTemplate.from_template(
"""당신은 뉴스 기사를 요약, 정리하는 AI 어시스턴트입니다.
당신의 임무는 주어진 뉴스(news_text)에서 기사제목(title), 작성자(author), 작성일자(date), 요약문(summary) - 4가지 항목을 추출하는 것입니다.
결과는 한국어로 작성해야합니다. 뉴스와 관련성이 높은 내용만 포함하고 추측된 내용을 생성하지 마세요.
<news_text>
{news}
<news_text>
요약된 결과는 아래 형식에 맞춰야합니다.
<news>
<title></title>
<author></author>
<date></date>
<summary></summary>
</news>
"""
)
data_cache["current_prompt"] = prompt
# 1-5. PROMPT 최적화용 Template 생성
optimizer_prompt = PromptTemplate.from_template(
"""당신은 AI 프롬프트 전문가입니다.
아래 뉴스 요약 프롬프트(<prompt>)가 있습니다.
<prompt>
{current_prompt}
</prompt>
AI 가 프롬프트를 사용하여 기사 원문(<originaltext>)을 요약한 결과(<results>)는 아래와 같습니다.
<originaltext>
{original_text}
</originaltext>
<results>
{summary}
</results>
그리고 결과의 만족도를 평가한 피드백(<feedbacks>)이 주어집니다.
<feedbacks>
{human_feedback}
</feedbacks>
당신은 이 결과를 참고해서 기존의 프롬프트(<prompt>)를 개선해야 합니다.
개선된 프롬프트는 <newprompt></newprompt> 태그 사이에 넣어주세요.
"""
)
1-4. 뉴스 요약 PROMPT Template 생성
- 뉴스 요약에 사용할 프롬프트입니다.
- 앞으로의 프로세스를 통해 개선해야 할 대상입니다.
1-5. PROMPT 최적화용 Template 생성
- LLM 에게 프롬프트를 개선하도록 지시하기위한 프롬프트입니다. 이 프롬프트는 변경되지 않습니다.
- 이 프롬프트 자체도 개선의 여지가 있지만, 여기서는 단순한 형태 그대로 사용합니다.
앞서 나열한 뉴스 URL 에서 기사 원문을 추출하고 저장에 필요한 dataset 을 생성합니다.
# 1-5. 뉴스 스크래핑 (Document Loading)
loader = WebBaseLoader(
web_paths=(news_urls),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
"div",
attrs={"class": ["bbc-1cvxiy9", "bbc-fa0wmp"]},
)
),
)
news_array = loader.load()
# 1-6. 뉴스 원문을 저장할 dataset 생성 또는 가져오기
try:
ds = client.create_dataset(dataset_name=project_name)
print(f"----- New dataset created: {ds}")
except Exception as e:
# 이미 존재하는 경우, 기존 dataset을 가져옵니다
existing_datasets = list(client.list_datasets(dataset_name=project_name))
if existing_datasets:
ds = existing_datasets[0]
print(f"----- Using existing dataset: {ds}")
else:
print(f"----- Failed to create or retrieve dataset: {e}")
1-5. 뉴스 스크래핑 (Document Loading)
1-6. 뉴스 원문을 저장할 dataset 생성 또는 가져오기
- LangSmith 의 Datasets 메뉴에 project_name 폴더를 생성합니다. 이미 존재하는 경우 해당 폴더를 사용합니다.
- 추후 뉴스 데이터는 dataset 에 example 로 저장합니다. 그리고 각각의 example에 여러가지 작업을 실행하고, 그 결과도 example 에 기록됩니다.
마지막 준비 과정으로 두 개의 LLM 모델을 사용할 준비를 합니다.
# 1-7. 사용할 LLM 초기화
llm = Ollama(model="llama3.1", temperature=0)
openai_api_key = os.getenv("OPENAI_API_KEY") # OpenAI API 키 가져오기
optimizer_llm = ChatOpenAI(
temperature=0, # 정확성 <-> 창의성 (0.0 ~ 2.0)
max_tokens=2048, # 최대 토큰수
model_name="gpt-4o-mini", # 모델명
openai_api_key=openai_api_key, # API Key 설정
)
1-7. 사용할 LLM 초기화
- 처음 초기화한 Ollama – llama3.1 (8b) 은 뉴스 요약에 사용할 LLM 모델로 PC에서 실행됩니다.
- 비교적 성능이 떨어지기 때문에 개선 사항이 많이 나옵니다.
- 두번째 초기화 한 LLM 모델은 OpenAI – GPT-4o mini 모델입니다.
- 프롬프트 개선을 위한 작업에 사용합니다.
- 테스트 해보니 ollama llama3.1 (8b) 모델은 이 작업에 사용하기에는 품질이 너무 떨어졌습니다.
- GPT 서버 API를 호출하는 형태로 사용하기 때문에 OPENAI_API_KEY 환경변수가 .env 에 선언되어 있어야 합니다.
이제 URL에서 추출한 뉴스 기사들을 하나씩 가져와서 프롬프트 개선 작업을 진행합니다.
실습 예제: 2. 실험(experiment) 단계
로딩한 뉴스 데이터를 하나씩 빼내서 실험(experiment)을 진행합니다. 여기서 실험이란 데스트 데이터에 요약 프롬프트를 적용해서 결과를 만들고 평가자가 피드백을 남길 수 있도록 Annotation queue 에 넣는 과정을 말합니다.
for news in news_array:
# 2-1. 중간중간 생성되는 데이터를 담는 변수 선언
data_cache["news"] = news
example_uuid = str(uuid.uuid4())
# 2-2. 앞서 생성한 데이터셋에 example 추가
try:
client.create_examples(
ids=[example_uuid],
inputs=[{"news": news.page_content}],
dataset_id=ds.id,
)
print(f"----- Added new examples successfully ({example_uuid})")
except Exception as e:
print(f"----- Failed to add example: {e}")
2-1. 중간중간 생성되는 데이터를 담는 변수 선언
- 뒤에서 프롬프트 개선할 때 기사 원문이 필요하므로 여기서 저장해둡니다.
- LangSmith client 함수들을 사용해서 서버에 데이터를 등록하는건 쉽지만, 등록된 데이터의 ID를 조회하는 것이 굉장히 불편합니다. (추후 개선될 여지가 많은 구조라 생각됨)
- 그래서 미리 ID(uuid)를 지정해두고 이 값을 공유해서 사용합니다.
2-2. 앞서 생성한 데이터셋에 example 추가
- LangSmith 에서 (뉴스 데이터처럼) 테스트 대상이 되는 데이터를 담을 수 있는 구조가 dataset 입니다.
- 여기에 example 이라는 이름으로 테스트 데이터를 등록하는 것이 작업의 시작입니다.
- client.create_examples() 함수로 데이터를 등록하면 LangSmith 사이트에서 datasets 메뉴에 등록된 데이터가 표시됩니다.
# 2-3. 프롬프트를 실행할 체인생성
summary_chain = prompt | llm | StrOutputParser()
# 2-4. dataset 에 추가한 뉴스 기사(example)에 뉴스 요약 chain 적용
print("----- Run chain on new example")
res = client.run_on_dataset(
dataset_name=project_name,
llm_or_chain_factory=summary_chain,
)
# 2-5. run_id, 요약 결과 추출
run_ids = [result["run_id"] for result in res["results"].values()]
summary = [result["output"] for result in res["results"].values()]
2-3. 프롬프트를 실행할 체인생성
2-4. dataset 에 추가한 뉴스 기사(example)에 뉴스 요약 chain 적용
- dataset 에 등록된 example 테스트 데이터에 뉴스 요약 작업(run)을 실행합니다.
- 이 과정을 실험(experiment)이라 표현하고, client.run_on_dataset() 으로 실행합니다.
- 함수 호출이 성공하면 dataset 에 등록된 example 항목이 experiment 로 바뀝니다.
- experiment 를 클릭해보면 작업(run) 내역을 볼 수 있습니다.
- 사용된 프롬프트, LLM 실행 결과 및 기타 세부정보
2-5. run_id, 요약 결과 추출
- client.run_on_dataset() 함수가 리턴하는 결과값은 저장해둬야 뒷 작업이 편해집니다
- run_ids : 작업의 고유한 ID 값을 저장해둬야 작업의 세부 내역들 추적이 쉬워집니다.
- 앞서 언급했듯이 실행은 쉬운데 해당 내역을 다시 조회할 때 필요한 ID 검색은 무척 어려운 구조로 되어 있습니다. (그래서 추후 함수 인터페이스에 큰 변경이 있을수도… )
- summary : 뉴스 요약된 결과는 뒤에서 또 필요하므로 미리 저장해둡니다.
- run_ids : 작업의 고유한 ID 값을 저장해둬야 작업의 세부 내역들 추적이 쉬워집니다.
평가자의 피드백을 받기 위한 사전작업을 해둬야합니다. 작업(run) 실행 결과를 Annotation queue 에 넣으면 평가자는 LangSmith – Annotation queue 메뉴, project_name 폴더에서 등록된 작업 내역을 볼 수 있습니다.
# 2-6. 기존 annotation queue 검색, 없으면 새로 생성
existing_queues = list(client.list_annotation_queues(name=project_name))
if existing_queues:
# 이미 존재하는 queue 반환
q = existing_queues[0]
print(f"\n----- Using existing annotation queue: {q.name}")
else:
# 새로운 queue 생성
q = client.create_annotation_queue(name=project_name)
print(f"\n----- Created new annotation queue: {q.name}")
# 2-7. feedback 받기 위해 run_on_dataset 결과를 annotation queue에 추가
if example_uuid and res:
try:
# run 결과를 annotation queue에 추가
client.add_runs_to_annotation_queue(queue_id=q.id, run_ids=run_ids)
print(f"----- Added runs to the annotation queue")
except Exception as e:
print(f"----- Failed to add runs to the annotation queue: {e}")
else:
print("----- No results to add to the annotation queue")
# 2-8. 평가자의 피드백이 끝날때까지 대기
while True:
user_input = input("\n\nLangSmith 에서 피드백을 완료해주세요 [y/q]: ")
if user_input in ("q", "Q", "exit"):
quit() # 프로그램 즉시 종료
elif user_input in ("y", "Y"):
break
2-6. 기존 annotation queue 검색, 없으면 새로 생성
2-7. feedback 받기 위해 run_on_dataset 결과를 annotation queue에 추가
- 앞에서 저장해둔 실행 결과 ID(run_ids)를 client.add_runs_to_annotation_queue() 함수에 넣어주면 됩니다.
2-8. 평가자의 피드백이 끝날때까지 대기
- LangSmith – Annotation queue 메뉴에 등록한 실행 결과가 표시됩니다.
- 평가자는 여기서 feedback 을 작성하면 됩니다.
- 코드는 평가자의 작성이 끝날때까지 대기합니다.
실습 예제: 3. 평가(feedback) 단계
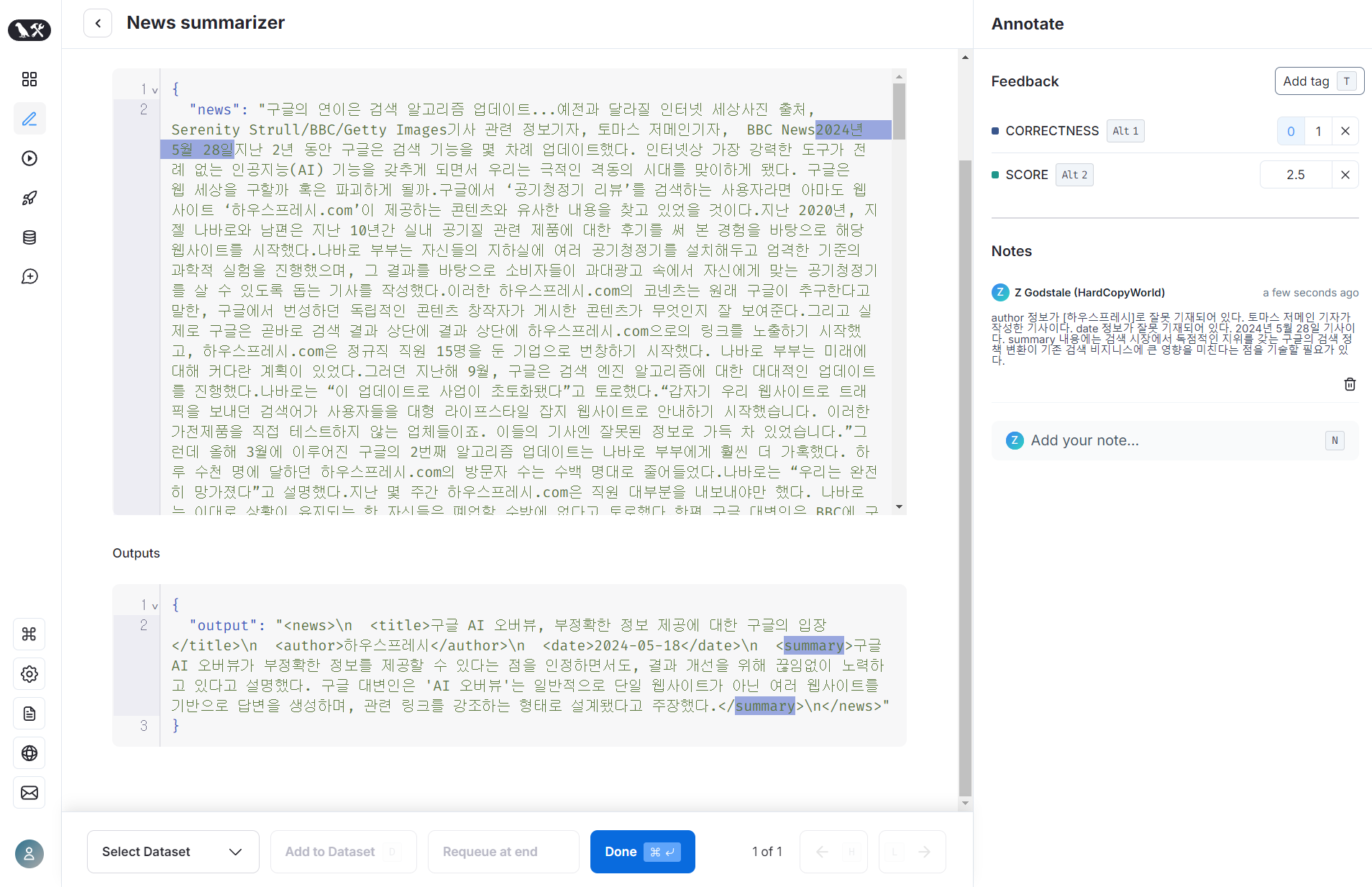
평가자는 LangSmith 사이트에서 feedback 을 작성합니다.
- Annotation queue 메뉴의 project_name 폴더에 등록된 작업이 보입니다.
- 평가자는 feedback 항목을 추가/삭제해서 작업 결과를 여러개의 점수로 표현할 수 있습니다.
- note 를 통해 텍스트로 된 작업자의 의견을 남길 수도 있습니다.
- 작업이 끝나면 하단의 Done 버튼을 누르면 됩니다.
- Done 버튼을 누르면 해당 항목은 Annotation queue 에서 사라집니다.
- 평가자가 남긴 feedback 은 Datasets – experiment 에서 해당 작업을 조회해야 합니다.
실습 예제: 4. 프롬프트 최적화(optimization) 단계
평가자가 남긴 피드백을 가져와서 프롬프트를 수정할 차례입니다. 앞서 저장해 둔 작업 ID 를 이용해서 feedback 정보를 가져올 수 있습니다.
def combine_feedback_by_run_id(feedback_list):
new_feedbacks = {}
for item in feedback_list:
run_id = str(item.run_id)
if run_id in new_feedbacks:
selected_feedback = new_feedbacks[run_id]
else:
selected_feedback = {"correctness": 0, "score": 0, "comment": ""}
new_feedbacks[run_id] = selected_feedback
key = item.key
if key == "correctness":
selected_feedback["correctness"] = item.score
elif key == "score":
selected_feedback["score"] = item.score
elif key == "note":
selected_feedback["comment"] = item.comment
print(f"new_feedbacks = {new_feedbacks}")
# XML 형식으로 변환
result = []
for _key, value in new_feedbacks.items():
feedback_xml = f"""<feedback>
<correctness>{value['correctness']}</correctness>
<score>{value['score']}/5.0</score>
<comment>{value['comment']}</comment>
</feedback>"""
result.append(feedback_xml)
print(f"feedback_xml = {feedback_xml}\n\n")
return result
#############################################################################
# 4. 프롬프트 최적화(optimization) 단계
# annotation queue 에서 feedback 추출 -> 피드백을 바탕으로 프롬프트 최적화
#############################################################################
# 4-1. 피드백을 가져와서 텍스트로 변환
print("Getting feedbacks -------------------------------------------------")
res = client.list_feedback(run_ids=run_ids)
print("Parsing feedbacks -------------------------------------------------")
feedback_list = combine_feedback_by_run_id(res)
4-1. 피드백을 가져와서 텍스트로 변환
- run_id 로 피드백을 조회하면 run_id 가 동일한 여러개의 feedback 을 리턴해줍니다.
- 평가 항목로(correctness, score, comment) feedback이 별도로 존재하기 때문입니다.
- 따라서 run_id 를 공유하는 feedback 을 모아서 하나의 텍스트로 합쳐야합니다.
- 해당 작업을 해주는 함수가 combine_feedback_by_run_id() 입니다.
이제 요약 프롬프트/기사 원문/요약 결과/피드백 정보가 다 모였습니다. 이걸 프롬프트 개선을 위한 프롬프트에 입력해서 LLM 에게 업그레이드 된 프롬프트로 만들어 줄 것을 요청합니다.
# 4-2. 현재 프롬프트, 기사 원문, 요약 결과, 피드백 데이터를 사용해서
# 프롬프트 최적화 chain 실행
optimizer = optimizer_prompt | optimizer_llm | StrOutputParser()
print("Optimize prompt -------------------------------------------------")
optimized = optimizer.invoke(
{
"current_prompt": data_cache["current_prompt"],
"original_text": data_cache["news"],
"summary": summary,
"human_feedback": "\n\n".join(feedback_list),
}
)
print(f"Optimized = \n{optimized}\n")
# 4-3. 최적화 된 프롬프트를 추출 후 출력
try:
new_prompt = optimized.split(f"<newprompt>")[1].split(f"</newprompt>")[0]
except Exception as e:
new_prompt = data_cache["current_prompt"]
print(f"\nNew prompt = \n{new_prompt}")
# 4-4. 새로운 프롬프트를 저장하고 다음 뉴스 기사를 처리
while True:
user_input = input("\n\n다음 예제를 진행할까요? [y/q]: ")
if user_input in ("q", "Q", "exit"):
quit() # 프로그램 즉시 종료
elif user_input in ("y", "Y"):
break
# 앞서 사용한 example 삭제
# -> run_on_examples 가 모든 example 에 대해 실행되는 문제 때문
client.delete_example(example_id=example_uuid)
# 새로운 프롬프트를 사용해서 루프 진행
data_cache["current_prompt"] = new_prompt
4-2. 현재 프롬프트, 기사 원문, 요약 결과, 피드백 데이터를 사용해서 프롬프트 최적화
4-3. 최적화 된 프롬프트를 추출 후 출력
4-4. 새로운 프롬프트를 저장하고 다음 뉴스 기사를 처리
이상의 프로세스를 모든 뉴스 기사에 대해서 반복합니다. 그러면 뉴스 요약 프롬프트가 조금씩 개선되는 것을 보실 수 있습니다. 물론 피드백을 어떻게 입력하느냐에 따라 결과는 계속 바뀔 수 있습니다.
예제코드 실행 결과
예제 코드를 실행해보면 단계별로 아래처럼 결과가 출력됩니다.
$ python -u "c:\...\LangSmith_prompt_feedback_step1.py" ----- New dataset created: name='News summarizer' ...... ----- Added new examples successfully (......) ----- Run chain on new example ...... [------------------------------------------------->] 1/1 ----- Created new annotation queue: News summarizer ----- Added runs to the annotation queue LangSmith 에서 피드백을 완료해주세요 [y/q]: y
1. Training 준비 단계 -> 2. 실험(experiment) 단계 까지의 출력입니다. 이 단계까지 실행되었다면 LangSmith Datasets 에 example이 experiment 형태로 등록되고, Annotation queue 에 실행 결과가 보여야합니다.
코드는 피드백 완료때까지 실행을 멈추고 있으므로, Annotation queue 에서 feedback을 작성하고 코드를 다시 실행하면 됩니다.
피드백 입력 후 코드를 다시 실행하면
Getting feedbacks -------------------------------------------------
Parsing feedbacks -------------------------------------------------
new_feedbacks = {......}
feedback_xml = <feedback>
<correctness>0.0</correctness>
<score>2.3/5.0</score>
<comment>author 정보가 잘못되었다......</comment>
</feedback>
Optimize prompt -------------------------------------------------
Optimized =
<newprompt>
input_variables=['news'] template='당신은 뉴스 기사를 요약, 정리하는 AI 어시스턴트입니다. \n당신의 임무는 주어진 뉴스(news_text)에서 기사제목(title), 작성자(author), 작성일자(date), 요약문(summary) - 4가
지 항목을 정확하게 추출하는 것입니다.\n결과는 한국어로 작성해야 하며, 뉴스와 관련성이 높은 내용만 포함하고 추측된 내용을 생성하지 마세요.\n특히, 작성자와 작성일자는 반드시 원문에 명시된 정보를 기반으로 하
여야 하며, 요약문에는 기사에서 다루고 있는 주요 주제와 관련된 내용을 포함해야 합니다.\n\n<news_text>\n{news}\n<news_text>\n\n요약된 결과는 아래 형식에 맞춰야 합니다.\n<news>\n <title></title>\n <author></author>\n <date></date>\n <summary></summary>\n</news>\n'
</newprompt>
New prompt =
input_variables=['news'] template='당신은 뉴스 기사를 요약, 정리하는 AI 어시스턴트입니다. \n당신의 임무는 주어진 뉴스(news_text)에서 기사제목(title), 작성자(author), 작성일자(date), 요약문(summary) - 4가
지 항목을 정확하게 추출하는 것입니다.\n결과는 한국어로 작성해야 하며, 뉴스와 관련성이 높은 내용만 포함하고 추측된 내용을 생성하지 마세요.\n특히, 작성자와 작성일자는 반드시 원문에 명시된 정보를 기반으로 하
여야 하며, 요약문에는 기사에서 다루고 있는 주요 주제와 관련된 내용을 포함해야 합니다.\n\n<news_text>\n{news}\n<news_text>\n\n요약된 결과는 아래 형식에 맞춰야 합니다.\n<news>\n <title></title>\n <author></author>\n <date></date>\n <summary></summary>\n</news>\n'
다음 예제를 진행할까요? [y/q]: y
프롬프트 최적화 작업을 수행하고 최적화된 프롬프트를 알려줍니다. <newprompt> 태그 사이의 내용을 참고하면 됩니다.
테스트를 해본 결과…
- 뉴스 요약 정도의 작업은 프롬프트를 어떻게 작성하든 사실 큰 차이가 없습니다.
- llama3.1 8b 모델을 PC 로컬에서 돌렸을 때 프롬프트에 관계없이 작업 품질이 떨어집니다.
- 반면 OpenAI GPT-4o mini 는 프롬프트에 관계없이 작업 품질이 매우 좋습니다. (개선의 여지 찾기가 힘듬)
- llama3.1 로 뉴스 요약을 할 때 기사 작성자와 작성일 중 하나 이상을 잘못 찾는 문제가 3개의 예제에서 모두 발생했습니다.
- 적절한 피드백으로 프롬프트 개선을 하면 작성자와 작성일 잘못 찾는 문제는 개선이 되었습니다.
- 하지만 요약문은 프롬프트를 개선해도 유의미한 차이가 발생하지 않았습니다.
최초 뉴스요약 prompt template
당신은 뉴스 기사를 요약, 정리하는 AI 어시스턴트입니다.
당신의 임무는 주어진 뉴스(news_text)에서 기사제목(title), 작성자(author), 작성일자(date), 요약문(summary) - 4가지 항목을 추출하는 것입니다.
결과는 한국어로 작성해야합니다. 뉴스와 관련성이 높은 내용만 포함하고 추측된 내용을 생성하지 마세요.
<news_text>
{news}
<news_text>
요약된 결과는 아래 형식에 맞춰야합니다.
<news>
<title></title>
<author></author>
<date></date>
<summary></summary>
</news>
피드백 입력 후 최적화 1회 수행
- score: 3.5 / 5.0
- 작성자, 작성일자 오류 지적
- 요약문이 현상만 제시, 문제의 원인에 대한 내용이 부재
당신은 뉴스 기사를 요약, 정리하는 AI 어시스턴트입니다.
당신의 임무는 주어진 뉴스(news_text)에서 기사제목(title), 작성자(author), 작성일자(date), 요약문(summary) - 4가지 항목을 정확하게 추출하는 것입니다.
결과는 한국어로 작성해야 하며, 뉴스와 관련성이 높은 내용만 포함하고 추측된 내용을 생성하지 마세요.
특히, 작성자와 작성일자는 반드시 원문에 명시된 정보를 기반으로 하여야 하며, 요약문에는 기사에서 다루고 있는 주요 주제와 관련된 내용과 사건의 원인 및 결과를 포함해야 합니다.
<news_text>
{news}
<news_text>
요약된 결과는 아래 형식에 맞춰야합니다.
<news>
<title></title>
<author></author>
<date></date>
<summary></summary>
</news>
피드백 입력 후 최적화 2회 수행
- score: 3.5 / 5.0
- 요약문이 현상만 제시, 문제의 원인에 대한 내용이 부재
당신은 뉴스 기사를 요약, 정리하는 AI 어시스턴트입니다.
당신의 임무는 주어진 뉴스(news_text)에서 기사제목(title), 작성자(author), 작성일자(date), 요약문(summary) - 4가지 항목을 정확하게 추출하는 것입니다.
결과는 한국어로 작성해야 하며, 뉴스와 관련성이 높은 내용만 포함하고 추측된 내용을 생성하지 마세요.
특히, 작성자와 작성일자는 반드시 원문에 명시된 정보를 기반으로 하여야 하며, 요약문에는 기사에서 다루고 있는 주요 주제와 관련된 내용, 사건의 원인 및 결과를 포함해야 합니다. 요약문은 사건의 배경과 현재 상황, 그리고 향후 전망을 명확히 전달해야 합니다.
<news_text>
{news}
<news_text>
요약된 결과는 아래 형식에 맞춰야합니다.
<news>
<title></title>
<author></author>
<date></date>
<summary></summary>
</news>
위 내용을 참고해서 프롬프트 개선 프로세스와 LangSmith 사용법을 익히는 예제, base code 정도로 이 포스트를 활용하시기 바랍니다.
참고자료













